
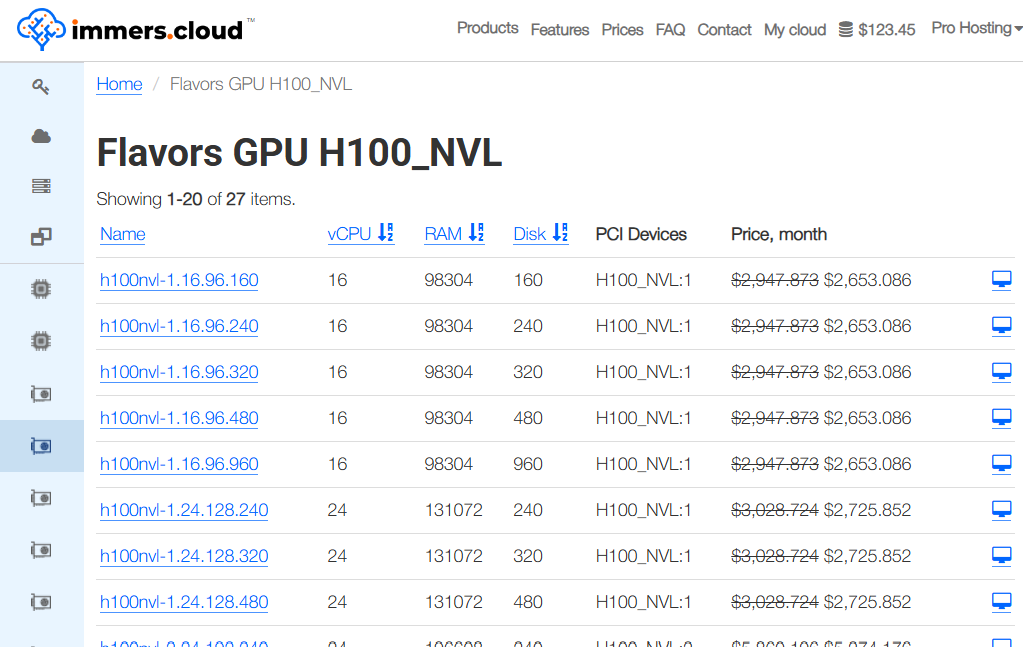
Cloud provider immers·cloud has announced the availability of servers powered by the NVIDIA H100 NVL 94GB GPU. This is a specialized version of NVIDIA’s flagship accelerator, designed for large-scale AI workloads and dense cluster environments — the kind where memory runs out faster than patience.
The new GPU is offered as part of immers·cloud’s cloud configurations and targets use cases where the standard H100 no longer feels sufficient, not due to lack of compute power, but because data simply refuses to fit.
What Makes the H100 NVL Different

NVIDIA H100 NVL. Image: igorslab.de
The H100 NVL variant stands apart from the standard H100 and is tailored for workloads that push data volume and parallelism beyond familiar limits:
-
94 GB of HBM3 memory, 14 GB more than the regular H100;
-
Up to 4 TB/s memory bandwidth, which becomes noticeable as soon as data movement turns into a bottleneck;
-
4th-generation Tensor Cores and the Transformer Engine with FP8 support, delivering up to 9× acceleration when training MoE models;
-
support for R535 drivers and newer, without version gymnastics.
Taken together, this results in an accelerator built not for short demos, but for sustained operation in distributed systems.
Where This Actually Makes Sense
The NVIDIA H100 NVL in immers·cloud is aimed at scenarios where compromises on memory and bandwidth stop being an option:
-
training and inference of large language models;
-
AI clusters with high data density;
-
workloads where stability matters more than headline benchmark numbers;
-
projects where GPU memory limits are a recurring issue, not an edge case.
In simpler terms, it is meant for situations where “just one more batch” has already become a design flaw.
Bottom Line
By adding the NVIDIA H100 NVL 94GB to its cloud offerings, immers·cloud has expanded its toolkit for heavy AI workloads. This accelerator focuses on memory capacity and bandwidth rather than decorative specs. It is not for everyone — but for those who need it, alternatives tend to run out quickly.